Automatically add partitions in Athena
Working mostly on Data Engineering, Machine Learning and Bayesian analytics.
Using S3 and Athena is great for data storage and retrieval using queries. But when I first started using it, one common problem that came up fairly quickly is: How can I add new partitions automatically? The issue was this: Partitioned data was getting created by some ETL process, but it did not getting reflected when querying in Athena.
There are a few ways to add partitions information for Athena:
MSCK REPAIR TABLEqueryALTER TABLE ADD PARTITIONSqueryAWS Glue Crawler
Partition projection
In this introductory article, we will go over these techniques.
MSCK REPAIR TABLE
If you have hive style partitions, this is the easiest one and typically the first thing most folks try. The command is simple:
MSCK REPAIR TABLE table_name
But it's also my least preferred option. The biggest reason is : It can be slow. If you have lots of partitions, then the command will take time to finish.
So why does MSCK REPAIR TABLE slow down?
There are a couple of places on the internet that discuss this problem quite well here[1] and here[2]. To summarize: It's because of recursively listing the directory structure for all the partitions + hive metastore checking/modifying the partitions.
How to automate?
Don't.
MSCK REPAIR TABLE is a nice command to know and use, but for the reasons above, unless the number of partitions you have is very small, it's not worth automating it. (If you must know, the process is almost identical to alter table method, just change the query).
ALTER TABLE ADD PARTITIONS
The second way is to directly add the partition information through Athena.
From the AWS documentation, the command syntax is:
ALTER TABLE table_name ADD [IF NOT EXISTS]
PARTITION
(partition_col1_name = partition_col1_value
[,partition_col2_name = partition_col2_value]
[,...])
[LOCATION 'location1']
[PARTITION
(partition_colA_name = partition_colA_value
[,partition_colB_name = partition_colB_value
[,...])]
[LOCATION 'location2']
[,...]
To summarize, this is an Athena query that we are trying to schedule.
How to automate?
The most familiar way should be either use a cron on a machine or schedule a lambda function. My preference is to use Lambda if there are already be one or more data engineering repositories. By using SAM, creating, deploying and maintaining a new lambda function becomes another piece of code.
Caveats
There are a couple of issues that need to addressing in this technique:
Permissions. Lambda functions need permissions to execute Athena queries. If you are using SAM, this can be provided in the template yml file as a policy. The simplest way is to use
AmazonAthenaFullAccesspolicy - but like the policy name says - it allows full access to Athena. An inline policy or a custom policy is probably the right way to go long term.Handling retries or error handling during lambda function execution. For example, if Athena is handling too many requests it might throw
TooManyRequestsExceptionso we will need to handle a case like that.
AWS Glue crawler
Glue crawler is an AWS tool that scans data from a data store and populates the Glue data catalog with metadata. Crawlers are fairly straightforward because you need to only point to the data source and configure it a little then it does most of the work for you.
How to automate?
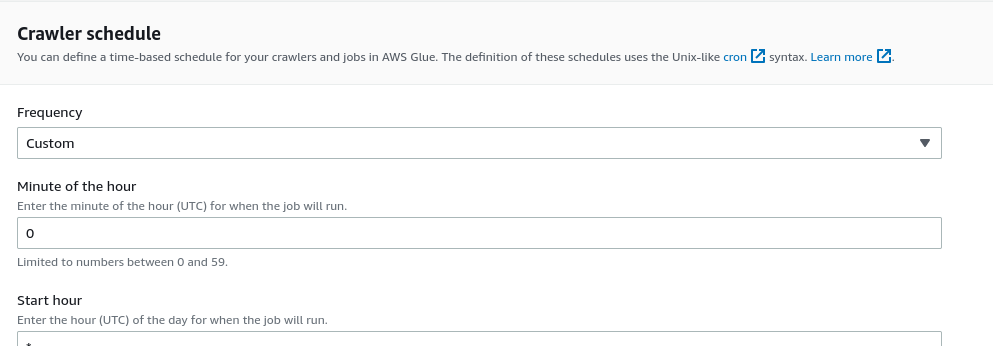
Triggering the crawler will update the metadata in the catalog. And Glue crawler gives you this option to do this crawler creation itself. In the last step, you can schedule the crawler at a number of frequencies (hourly, daily, weekly, monthly, or custom schedule with a cron syntax).
Caveats
A word of caution when using Glue crawler: In my opinion, if the structure of your data like schema, partitions, etc do not change that much then it is quite convenient. But if for example, your schema changes over time, then in my experience, Glue crawler has been a hit or a miss.
Athena partition projection
The last approach and in my opinion the one that should be used, is partition projection provided by Athena. In short, what it does is it gets the partitions information from the table properties directly instead of loading the partitions from AWS Glue Catalog and then pruning them.
How to automate?
Getting started with partition projection is fairly easy. As mentioned, we need to add this projection information into the table properties used by Athena.
We can do this through AWS Glue Catalog if you have existing tables. Steps:
Click on your table in the catalog.
Click on Edit table.
Then in the table properties section, add key-value pairs based on the data type of partition you want to add.
For example, a common data type for partition is date. For the date type, there are three required key-value pairs: projection.columnName.type , projection.columnName.range and projection.columnName.format. Respectively, these are used to specify the data type of the partition which in this case is date, the range which is a comma separated two element list that specify the minimum and maximum of values, and the date format (eg: dd-MM-yyyy). There are other data types which are supported as well: enum, integer and "injected". Each of them come with their own key-value pairs for using partition projection. Refer here[3] for more information on supported data types.
If you are creating new tables through Athena, you can add the key-value pairs in TBLPROPERTIES in the create table query.
There is a lot more to it than what we can talk about partition projection, it is quite a powerful feature. I highly recommend referring to the AWS docs[4] for more.
Summary
In this article we looked at a few techniques to add partitions in Athena and some of their associated pros and cons. In most situations, partition projection should work out just fine. But if you ever come across a situation where it does not, then I hope the other techniques can come to your aid. I'll try to add code to some of these techniques in the future to help illustrate these techniques further.
References
[1] https://athena.guide/articles/msck-repair-table/
[4] https://docs.aws.amazon.com/athena/latest/ug/partition-projection.html