Parquet format - A deep dive : Part 2
Demystifying how Parquet works internally

Working mostly on Data Engineering, Machine Learning and Bayesian analytics.
In this article we will get into how data is written as parquet format. To do that, one of the first thing we must do is talk about Dremel.
Dremel was built at Google, it is web scale analytical system for performing ad-hoc queries on nested data. Parquet takes a page from Dremel and uses its record shredding and record assembly algorithms to store and retrieve nested data efficiently.
Record shredding is how data is broken into columnar data, and then written into parquet files. The reverse procedure (record assembly) is covered in part 3.
Nested data
Before beginning, let's take a step back and look at the structure of the incoming data. Speaking generally, it can have the following characteristics:
Nested sections
Repeatable sections
Optional or required sections
This can be understood better when represented with a schema.
Schema
A schema is a structural view of the data. Let's use the same example as in the Dremel paper:

Minor note: The Dremel paper uses Protobuf[1] to represent the schema but you can use other protocols like Thrift[2] as well.
Looking at the above schema in a different way, we can think of it as a of group of nodes of size n >= 1 which are optional / required / repeating. The parquet format requires that we attempt to convert this into a flat structure.
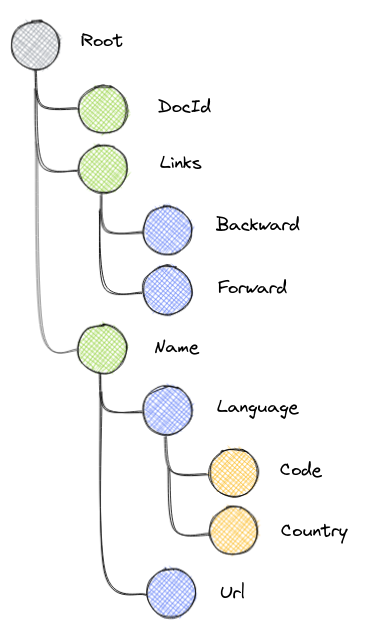
All the values of this structure are present in the leaves of the tree. Looking at it another way, the data can be flattened if we know the full path to the leaf + we know the depth of the node + we are able to represent optional / required nodes + we can represent if the repetition of fields. In other words, if we can reduce each path to a column and are able to generate this metadata for the nested incoming data, then along with the actual values themselves we have everything we need to convert the nested data into a flattened form.
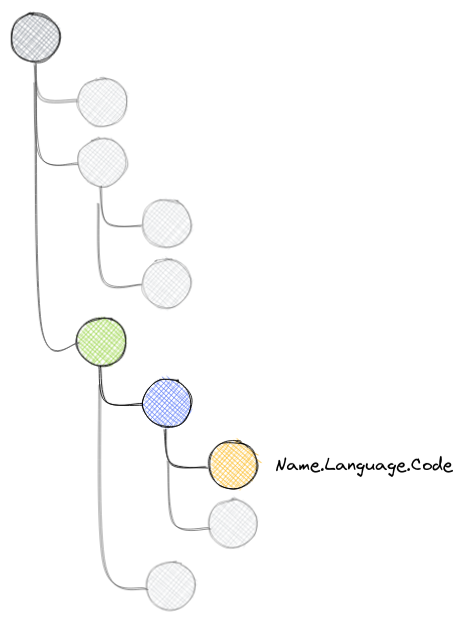
In the above example, if we look at the schema, Name.Language.Code is part of Name node which can repeat, Language node which can also repeat and Code is required. Thus for each Name.Language.Code value that exists in the data, if we can somehow capture the levels in the tree at which it repeats, and whether there are any optional along with the value then in principle we have everything we need to convert to and fro. This is what repetition levels and definition levels do.
To understand this better, let's go over them with an example.
Repetition level
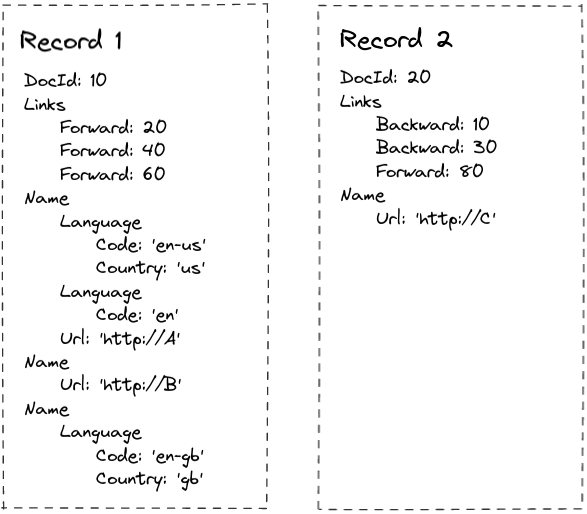
When we have nested data with multiple levels and there can be data at some level that is a) optional and b) repeated (ie, a list) we need to know one thing : At what level should I start create a new list for this value? In the Dremel paper this idea is defined as: "It tells us at what repeated field in the field’s path the value has repeated.". In the above example, let's look at the Name.Language.Code path (column) again.
Observations:
Going by the schema,
NameandLanguageare groups which can be repeated. They do in fact repeat in record 1.Namenode repeats three times,Languagenode repeats twice in the first name node, and once in the last one. And it occurs just once in record 2.Codeis a required field. Which means ifLanguageexists,Codemust exist as well as per the schema otherwise it is an invalid document.
Let's try to flatten this. Appending a number for simplicity and going in order, we have the following observations:
Field | Value | Create new list for this value? | New record? |
Name.Language.Code(1) | en-US | Y | Y |
Name.Language.Code(2) | en | N | N |
Name.Language.Code(3) | NULL | - | N |
Name.Language.Code(4) | en-gb | Y | N |
Name.Language.Code(5) | NULL | - | Y |
The above observations can be encoded by a single number called repetition level with the following rules:
For a new record, use the number 0. The list is created implicitly as well.
For an existing record, if the list needs to be created, use the level at which the list is going to be created.
For an existing record, if the list does not need to be created, use the level at which the element is being added.
Rewriting the table above with repetition level this time, we get for Name.Language.Code:
| Value | RL |
| en-US | 0 |
| en | 2 |
| NULL | 1 |
| en-gb | 1 |
| NULL | 0 |
Definition level
What is remaining is that for nested data, we need a way to represent optional values along the field path, particularly if it happened to be NULL.
If the data is present, this is the "normal" case. If it is not, then we need a way to tell where along the field path this data became NULL.
Putting it another way: Definition level is mostly useful when we have a) nested structure + b) optional fields that leads to NULL values. We will be able to recreate the missing pieces in a record if we know to be missing.
Let's take two examples this time. Name.Language.Code and Name.Language.Country. Here, Code is required but Country is optional. Name and Language are repeated groups which can be optional.
As before, for Name.Language.Code we have:
Field | Value | Upto which level optionals exist? |
Name.Language.Code(1) | en-US | 2 |
Name.Language.Code(2) | en | 2 |
Name.Language.Code(3) | NULL | 1 |
Name.Language.Code(4) | en-gb | 2 |
Name.Language.Code(5) | NULL | 1 |
For Name.Language.Country , we have:
| Field | Value | Upto which level optionals exist? |
| Name.Language.Country(1) | us | 3 |
| Name.Language.Country(2) | NULL | 2 |
| Name.Language.Country(3) | NULL | 1 |
| Name.Language.Country(4) | gb | 3 |
| Name.Language.Country(5) | NULL | 1 |
Observe the slight difference between the two tables, and that is only because Code is a required field. And for a required field, the definition level does not apply, therefore the DL value is reduced slightly.
Flattened structure
The full flattened structure for all the fields can be found in Dremel's paper. For brevity, here are couple additional example for Links node, ie, Links.Forward and Links.Backward.
Links.Forward
| Value | RL | DL |
| 20 | 0 | 2 |
| 40 | 1 | 2 |
| 60 | 1 | 2 |
| 80 | 0 | 2 |
Links.Backward
| Value | RL | DL |
| NULL | 0 | 1 |
| 10 | 0 | 2 |
| 30 | 1 | 2 |
Record shredding
With the key concepts above, we can look at the record shredding algorithm.
To recap, we want a way to convert nested data to flat data with additional metadata that helps preserve this structural information. Repetition levels and definition levels precisely do this.
First, lets referring to the Dremel's paper again for the pseudocode:
procedure DissectRecord(RecordDecoder decoder, FieldWriter writer, int repetitionLevel):
Add current repetitionLevel and definition level to writer
seenFields = {} // empty set of integers
while decoder has more field values
FieldWriter chWriter = child of writer for field read by decoder
int chRepetitionLevel = repetitionLevel
if set seenFields contains field ID of chWriter
chRepetitionLevel = tree depth of chWriter
else
Add field ID of chWriter to seenFields
end if
if chWriter corresponds to an atomic field
Write value of current field read by decoder using chWriter at chRepetitionLevel
else
DissectRecord( new RecordDecoder for nested record read by decoder, chWriter, chRepetitionLevel)
end if
end while
end procedure
What we are basically trying to do is walk down the nested record recursively preserving the level information. Let's take a very high level view and break down the logic:
RecordDecoder decodes binary records.
Each of the fields have a writer associated with them.
As we traverse down the tree, we maintain the repetition level and definition levels keeping in mind how they work from the previous sections.
If we encounter a node that does not have children (either NULL or some primitive type) we store the repetition level and definition level, otherwise we recurse further down.
Once we are done with the write procedure, the data is written to column chunks using the appropriate encoding mechanism.
And that's it! In part 4, we will go over some of the code, classes involved in making this happen. If you want to check out the code right away, navigate to the write and writeGroup method of GroupWriter.java in parquet-hadoop module in the parquet-mr library. It provides an example reference implementation.
Summary
In this article, we looked at how parquet converts nested records into flat data with some additional metadata to preserve the nested structure. In the following articles, we will look at how to recreate the original record from this data and will take a peek under the hood in parquet-mr and spark codebase on how this happens as well.
References
[1] Protobuf: https://developers.google.com/protocol-buffers/
[2] Apache Thrift: https://thrift.apache.org/