Parquet format - A deep dive : Part 4
Demystifying how Parquet works internally

Working mostly on Data Engineering, Machine Learning and Bayesian analytics.
After a lot of theory it's finally to talk about the code. Since there is a lot going on in the codebase, this will still be quite high level but it should serve as a good starting point.
parquet-mr consists uses maven multi modules approach, the modules that I found myself spending the most time on are: parquet-common, parquet-column, and parquet-hadoop. The codebase follows object oriented principles beautifully so there are many classes. But, the responsibility of each is very specific and it all comes together very elegantly to perform the operations required.
Note: This is a simplified class diagram with many classes missing, and some liberties taken with the associations, inner classes and so on. The overall structure roughly falls along the same lines.
Writing data
Here is a rough class diagram for the write process.
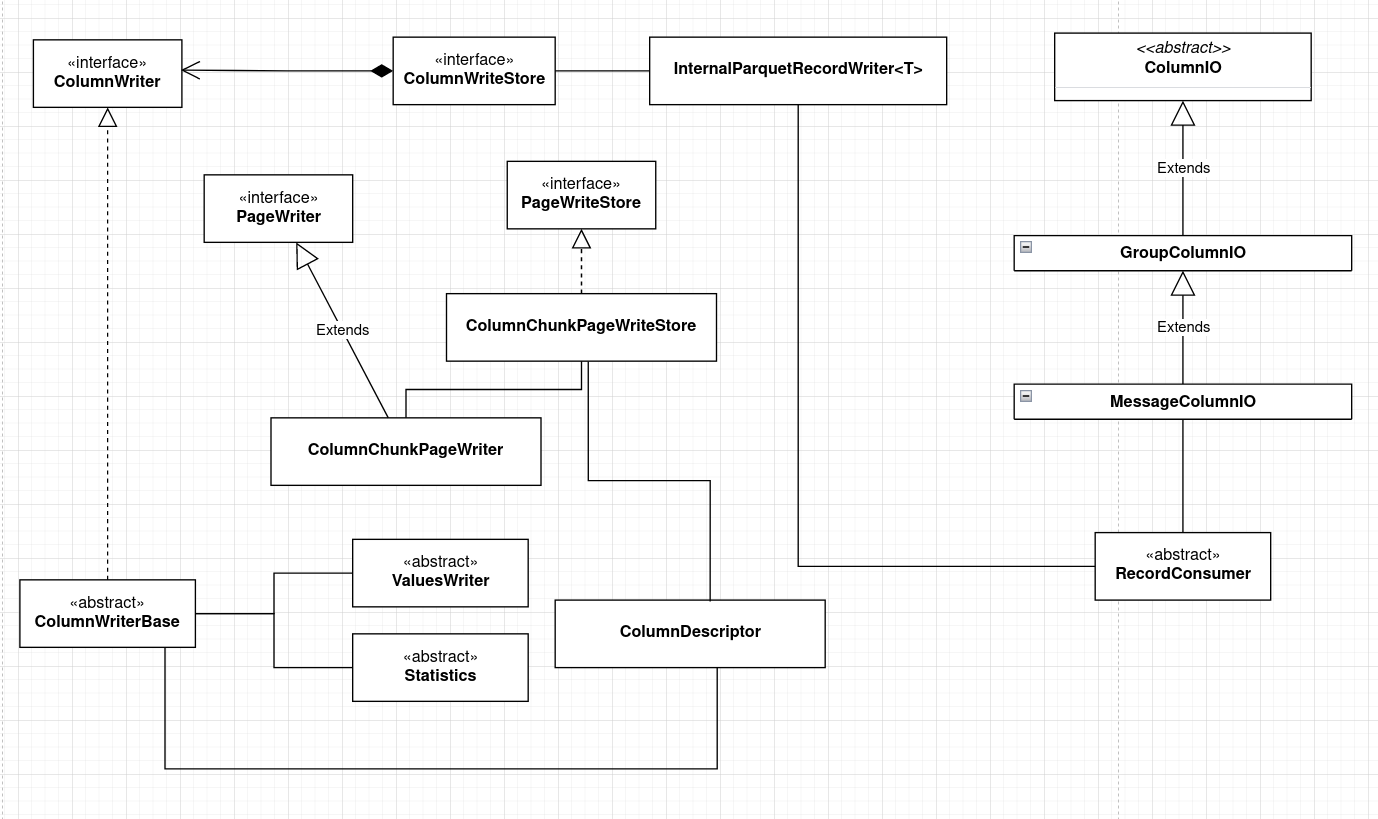
There are various classes that handle writing data into pages, column chunks and so on.
Each column of data has a ColumnDescriptor which describes its path, type and holds the maximum repetition level and definition level. This along with ColumnChunkPageWriter for each column form the collection of writes for each column through which data is written. This is maintained in the ColumnWriteBase subclasses which itself is generated for the specific column, from a provider through ColumnWriteBaseStore and its subclasses.
The actual writing itself happens through InternalParquetRecordWriter<T> in the parquet-hadoop module. During writing, we must keep in mind the encoding in which data is written, this happens through subclasses of ValueWriter , and since the record itself can have a nested structure, it needs to be serialized-deserialized appropriately which is done through ColumnIO and its subclasses. Finally, subclasses of Statistics maintain the metadata through which optimizations are performed for the read side.
Reading data
Class diagram for the read process.
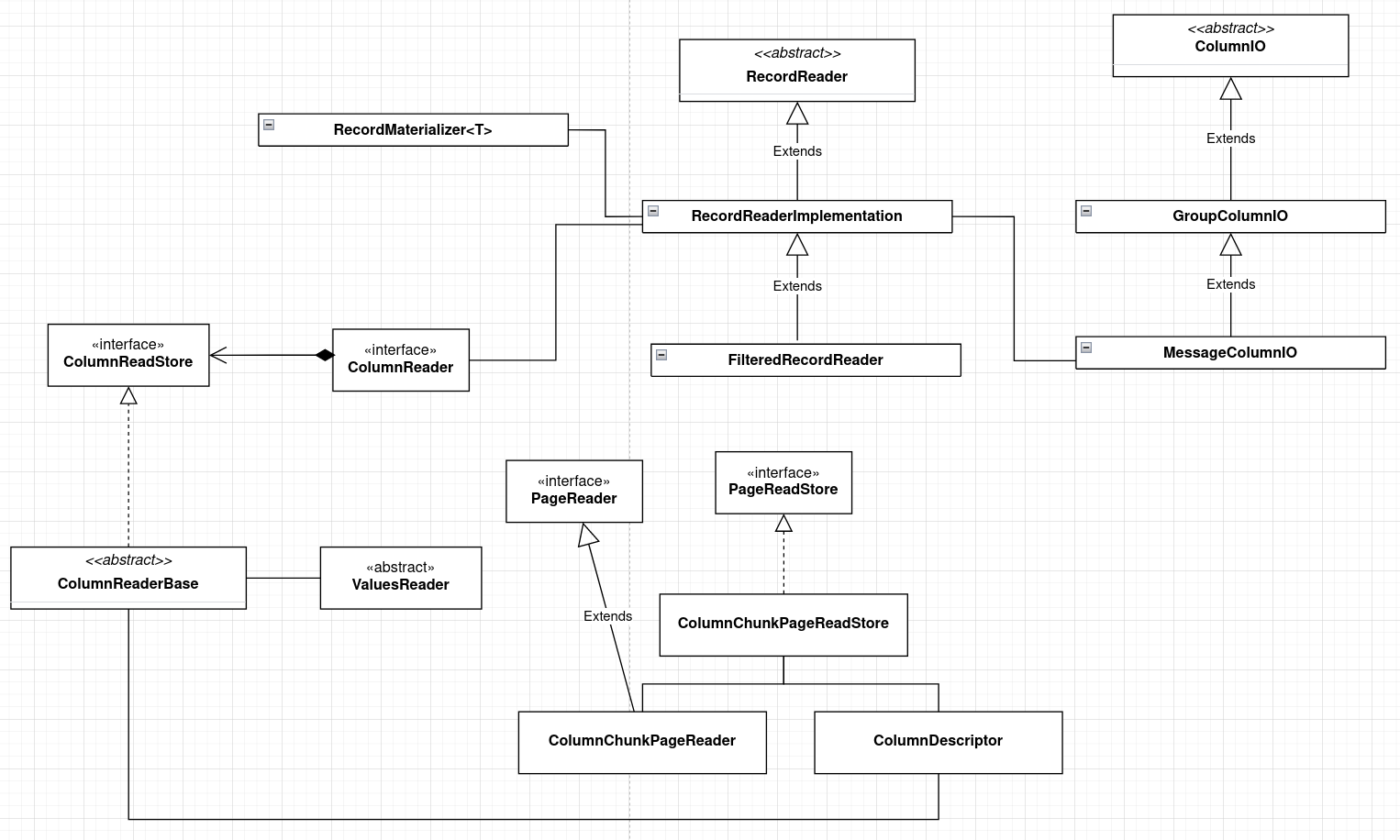
As you can see, there are prats of the diagram that are structurally very similar to the write side of the equation, except it performs the read operations.
Skipping over the counterparts which are mirrored from the write side, the new claases here are primarily RecordMaterializer and RecordReaderImplementation. RecordMaterializer has subclasses converts the read data into the appropriate format.
For example, Avro uses AvroRecordMaterializer, Protobuf uses ProtoRecordMateralizer and Spark uses ParquetRecordMaterializer.scala. RecordReaderImplementation is used to assemble the records and read its data, it constructs the automaton in the previous post used to read the shredded records, and holds a reference to the materializer.
Summary
And with that, we come to the end of the four part series. There's of course a lot more that I had to skip out, I highly recommend browsing through the parquet-mr codebase to get a sense for what this file format can do.
Personally, reading the code in parquet-mr was a difficult but rewarding experience. I do not claim to have understood it perfectly, but it was certainly a fun trip navigating through it and trying to figure things out. Shout out to the devs for this incredible project!