Using Google Cloud Run to process batch jobs

Working mostly on Data Engineering, Machine Learning and Bayesian analytics.
Cloud Run helps you deploy containerized workloads at scale. Using it as a backend for web server use cases is quite well known, but it also can be very useful for large batch jobs that tend to be CPU heavy, especially if the job can be divided into smaller independent pieces. This will be the central focus of this article.
The first half talks briefly about Cloud Run Jobs, and in the second half we will explore a very simple use case with sample code.
Use cases
In a nutshell: Long running jobs! Many use cases that I can think of fall neatly in the data processing or ML category:
You have a transactional database and need a way to compute aggregations of data without overwhelming the database.
Download and process data from a third party API.
Preprocess data stored on GCS and you cannot use Spark (for whatever reason).
How does it work?
Cloud Run Jobs can be divided into the following components:
Container. The actual workload to be executed.
Job. It is a higher level construct that references the container workload to run, specifies number of Tasks (refer below), accepts parameters during job creation and so on.
Task. This is the basic unit of parallelism run for a Cloud Run Job. A Task is an executable container instance. Cloud Run can spin up multiple tasks to parallelize your workload. Understanding this is the key to understanding how Cloud Run Jobs work.
In essence, a Cloud Run Job is a template that you fill in which is then later executed by the system. The mandatory fields are:
Job name.
The container image url.
GCP region.
Number of tasks.
Task timeout.
Task retries.
For a full list, it is informative to glance at the gcloud CLI command: https://cloud.google.com/sdk/gcloud/reference/run/jobs/create. You can see it accepts several other options such as container arguments, cpu and memory allocated for the container instance and so on.
Understanding Tasks
Tasks are the most important aspect of working with Cloud Run Jobs when it comes to parallel processing.
There are two key points to note:
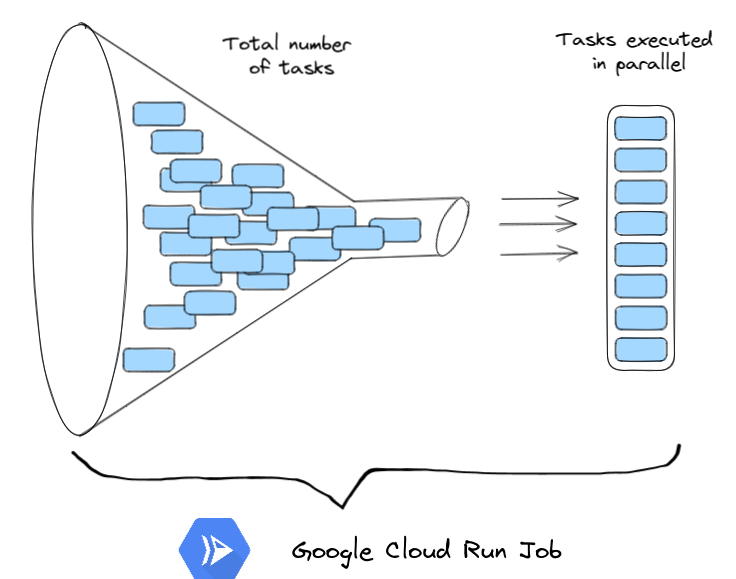
Task parallelism. The total number of tasks specified may be different from the total number of Tasks being executed in parallel.
Task independence. Since there are many tasks being executed in parallel, a question that tends to come up is: Are all these tasks executing the same container or can we somehow get each task to execute something different?
Let's get a little deeper into these two concepts and then work through it with a very simple example following that.
Task parallelism
For the sake of explanation, let us say that we have a dataset of 100 users and we want to analyze the user records. We can specify the number of tasks to be 100, but it may be that we can specify only 10 tasks to be executed in parallel.
But why only 10 and not all 100 in parallel? Well for one, there are regional limits enforced by Cloud Run (https://cloud.google.com/run/quotas). Other reasons could be more technical, say for example, we wouldn't want to overwhelm databases downstream by slamming them with workloads from parallel tasks.
Regardless, the important thing to remember is: These two can be different numbers.
Task independence
We know that Tasks are container instances being executed in parallel. For large batch jobs or long running jobs, it would be perfect if we divide our work into smaller pieces and somehow tell each Task to execute these pieces independently, in parallel.
Cloud Run lets you know which task (which container instance) it is currently executing and the total number of tasks it has through environment variables:
CLOUD_RUN_TASK_INDEX: The task index in this Job. With this, we can know the index of the task which is being executed.CLOUD_RUN_TASK_COUNT: The number of tasks in this Job that are being executed in parallel at any given time.
Note that "maximum number of tasks" is different from "maximum number of tasks running in parallel". The image above should demonstrate the difference. Referring to the resource limits page again, we see the total number of tasks spawned at once can be in the thousands range but the number of tasks being executed in parallel is in the hundreds range. The tasks must wait for their turn.
Let's now look at how we can use these two variables to retrieve some data and process it independently, we achieve our goal.
Example: Calculating daily user revenue
Here is our scenario:
We are running an e-commerce website with a transactional db.
We have a dataset of 100,000 users from a
Userstable.There is another table
Purchaseswith records that reference a user whenever a user purchases something on the website.For simplicity, the user ids are sequential integers starting from 0.
The coding language is Python.
Our goal: Create a job computes the total revenue from a user for that day. Store it in another table called Revenue.
Code
Note: The code is a contrived example and far from production grade code, but it is enough to demonstrate the two key pieces : CLOUD_RUN_TASK_INDEX and CLOUD_RUN_TASK_COUNT.
def compute():
task_index = int(os.environ["CLOUD_RUN_TASK_INDEX"])
task_count = int(os.environ["CLOUD_RUN_TASK_COUNT"])
user = os.environ["MYSQL_USER"]
password = os.environ["MYSQL_PASSWORD"]
db_name = os.environ["MY_DATABASE"]
num_users = 10000
batch_size = num_users / task_count
start_user_id, end_user_id = [int(batch_size * task_index), int(batch_size * (task_index + 1) - 1)]
Use task_index to retrieve a set of data points. Since the user ids are incremental in our case, we calculate the batch size based on the total number of tasks that can run in parallel at any given time, which can be used to retrieve the set of user ids to work on.
# Retrieve user ids
user_ids = session.execute(
text(f"""
SELECT user_id
FROM Users
WHERE user_id >= {start_user_id} and user_id <= {end_user_id}
""")
)
Here we see that we're using a simple select query based on the user id range retrieved above. It should be apparent right away that this is a potential bottleneck, and as mentioned above, one way to mitigate this to some extent is to select the task count environment variable judiciously. The same idea applies when we want to compute and store the result in the database. In other words, any service that is dependent on cloud run task execution must be able to handle the incoming load.
The full code is at: https://github.com/raghuveer-s/example-code/tree/main/cloud-run-jobs
Creating the job
This step is quite intuitive with the google cloud console. You can also do the same with the CLI or SDK if it suits your workflow.
In GCP, you can use the artifact registry (or the older container registry) as a registry for your container. Refer to this link: https://cloud.google.com/artifact-registry/docs/docker/pushing-and-pulling for more on how to do this.
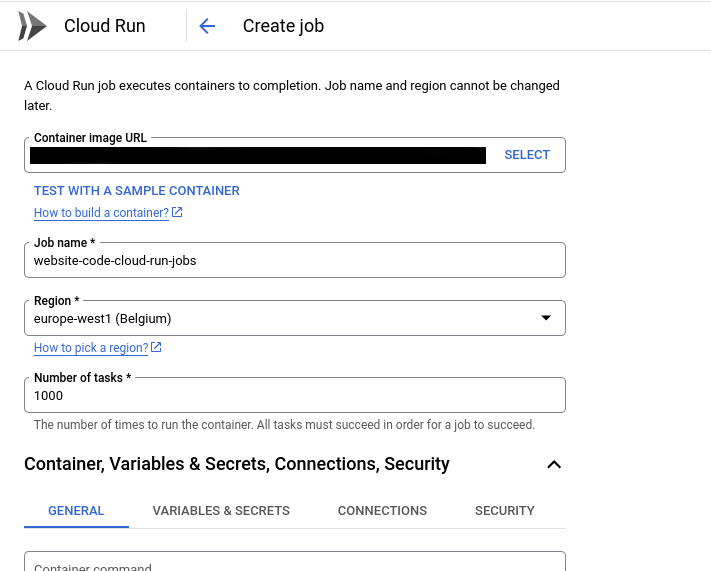
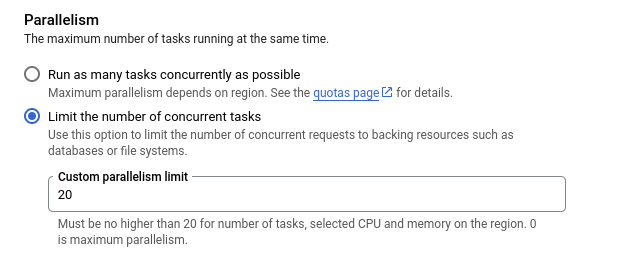
Towards the bottom of the screen, you can specify the total number of tasks that can execute in parallel, i.e, task count.
Once you are ready, just click the create job button and Cloud Run will do the rest.
Summary
Cloud Run jobs are well suited for large batch jobs. In this case we chose to do data processing, but it can be any long running divisible computation.
Use the task index to retrieve the subset of work we wish to perform computation on. Use task count to control number of parallel executing tasks.
Be mindful of services upstream and downstream if any.
Cloud Run has resource limits which vary by region. Refer to this page: https://cloud.google.com/run/quotas to know more about the limits on number of maximum tasks, and number of parallel tasks.