A Practical Introduction to Google Cloud Dataform
Building data pipelines in Dataform

Working mostly on Data Engineering, Machine Learning and Bayesian analytics.
Dataform is a tool that creates data pipelines using SQL. If you’re familiar with Dbt, Dataform is probably best understood as Dbt-esque tool that integrates really well with BigQuery and other Google Cloud products. In a short amount of time, it’s quickly grown to become one of my favorite tools in the data space. I cannot overstate how much it simplifies creating reliable and scalable pipelines. In this post, we’ll quickly go over its components and illustrate with a working example.
Note: We use Dataform v3 which changes things a little from the v2 version.
Architecture
Let’s start with some key pieces that we work with in Dataform.
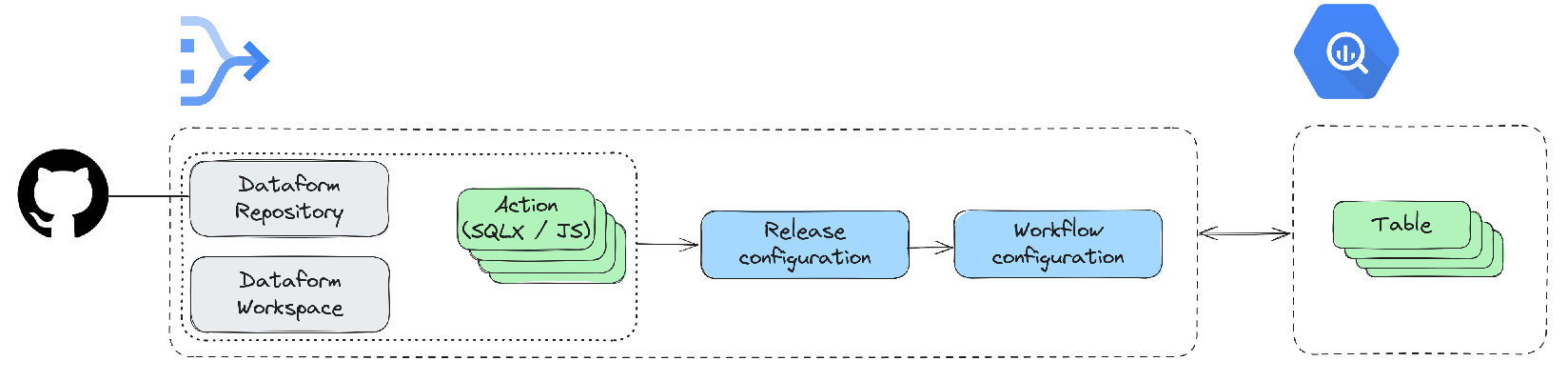
Going on by one:
Dataform Repository: The place to store the pipeline code. Every Dataform project needs to have a Repository as a top level object. We can connect the Dataform Repository to a Git Repository.
Dataform Workspace: Online editor where we can edit the code.
SQLX: Dataform has extended SQL a little to make it easier to define pipelines, it’s dependencies and so on. Eventually it all gets compiled into SQL.
Javascript: We can use Javascript along with SQLX. Even node modules can be installed, which is pretty cool!
Action: The smallest executable unit. Most of the time it’s SQLX code.
Workflow: A collection of Actions. This is the pipeline, essentially. When run, Dataform calls it “creating a workflow invocation”.
Release configuration: The result of compiling the SQLX files in the codebase. The compilation can be parameterized by passing in variables.
Workflow configuration: A workflow configuration is the set of Actions chosen to be executed.
BigQuery: Provides source and destination tables.
Creating the pipeline step-by-step
A word on permissions before we begin
There are two principals who needs permissions:
Dataform service account (which is created automatically when repository is created in the next step).
The user administering dataform settings.
Refer to these documents for more:
But if you don’t want to read the docs and are in a position to grant yourself additional roles (lucky you), then add roles/bigquery.dataEditor, roles/bigquery.user, roles/secretmanager.secretAccessor to the dataform service account, roles/dataform.admin to the user and keep cracking on.
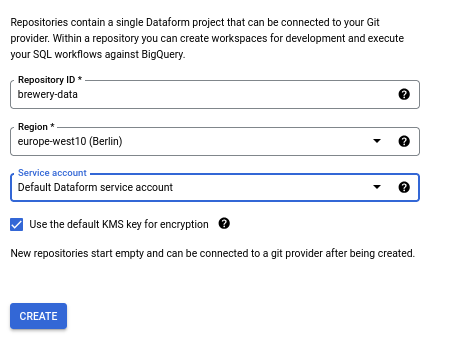
Create and connect the repository
A “Dataform repository” is a top level concept. It hosts the code that makes up the pipeline. It can be connected to a Git Repository.
To connect to a remote Git repo, just click on the “Connect with Git” and follow the UI. You will need to create a Secret and store it as well which allows you to connect securely to the Git repository. Both of these steps need adequate permissions.
Optional: Create a development workspace
The docs define a Workspace as “an editable copy of your repository”. It’s more easily understood as an online editor UI for code. It allows users to work independently directly on the UI online, commit their changes to git, execute workflows and so on. I’ve found it useful for quick prototyping and visualizing the pipeline DAG.
Local development environment
For Dataform, I use VSCode. There’s even a Dataform extension that comes in useful for a good development environment.
To get started, follow these steps:
Search and install the Dataform extension for VSCode. This provides syntax highlighting and on the fly compilation which can detect errors early in the development cycle.
Create a local folder for the code and step into it.
Install the
dataformpackage through node:npm i -g @dataform/core.Execute
dataform init . <gcp_project_id> <bigquery_dataset_location>. Usedataform helpto see what other options there are.
My dataform core version is 3.0.7 (the release notes can be tracked here: https://cloud.google.com/dataform/docs/release-notes) and as of this version, it creates three things:
definitionsfolder: Home for the.sqlxand.jsfiles.includesfolder: Home for common Javascript constants or functions.workflow_settings.yaml: These are default settings for the Dataform workflow. It consists of the dataform-core version being used, as well as the default project, dataset and location of the BigQuery data. These variables can be overridden. We will go in more detail a bit later.
Quick note: This step differs based on the Dataform version being used. I’m using v3.0.7, which uses yaml as part of the setup. Prior versions would have had dataform.json, package.json and node_modules in the setup. For more: TODO
Data
The dataset we’ll use is the Brewery dataset again (https://www.kaggle.com/datasets/ankurnapa/brewery-operations-and-market-analysis-dataset/). For our purposes, let’s compute the daily sales of beer grouped by area. From a pipeline perspective, this follows the classic flow: source → transform → sink executed at a daily cadence with some scheduler.
Code
We have everything we need to begin, let’s look at code. Here is the Git repository for reference: https://github.com/raghuveer-s/brewery-dataform/tree/basics-with-workflow-settings
First, let’s take a moment and look at the different pieces of a SQLX file:
A config block. This is a section that which defines type of workflow object, dependencies, tags, options for BigQuery table and more.
SQL operations for data transformations.
Pre and post operation blocks.
And that’s it. Now let’s map to our objective of computing daily sales.
Steps:
Create a declaration workflow object (Dataform defines different types of workflow objects, refer: https://cloud.google.com/dataform/docs/sql-workflows).
All this does is tell Dataform where a source table is and keeps a reference to it, which means all you need is a config block with details that point towards this table.
While this step is optional, I often prefer to create declarations. It helps keep the rest of the code consistent, and best of all, it can be visualized as a DAG in the workspace online.
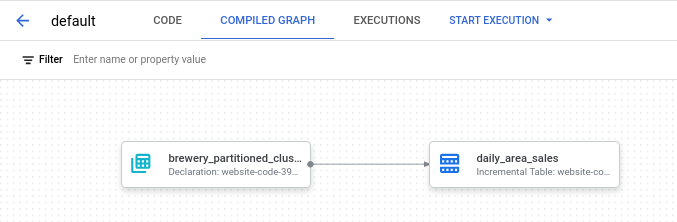
Create a SQLX file:
Since we are talking about data pipelines here, the result of our data transformation needs a home. We can have a table gets completely populated with this result or we can have table that has new data appended to it. The later is called “incremental” workflow object, the former is called “table”. Again, refer here: https://cloud.google.com/dataform/docs/sql-workflows
In the config block, specify:
Workflow object type as incremental.
Tags. These will be useful when we look at “workflow configurations” in the section below.
BigQuery options to the table that is going to hold the result of the transformations.
What follows is the actual SQL that do the work. In this case, we just sum up the sales that happened in a day and group it by area. Pretty simple.
The incremental table code has another section as well. We talked about config block and SQL, Dataform allows optional pre_operations and post_operations blocks as well. As one might expect, the code in this is run before and after the SQL transformations.
There are three methods that can be seen in the code: when(), incremental() and self(). These are some of the so-called “context methods”. when() provides conditional capabilities, incremental() returns true if the table being built is incremental or not, and self() is used to reference the current table being built.
So taken together, what we are doing is just establishing a checkpoint to be used in the where clause, and we start appending latest data if the table exists and is incremental. If not, then we take all the data in the source starting from 2023-01-01.
For more about pre and post operations, refer here: https://cloud.google.com/dataform/docs/table-settings?hl=en#execute-sql-before-table . And for context methods, there are a few more that can be used, refer here: https://cloud.google.com/dataform/docs/reference/dataform-core-reference#itablecontext.
Commit and push. If you have created a workspace online, then you may also see this error on the right complaining that a table does not exist:
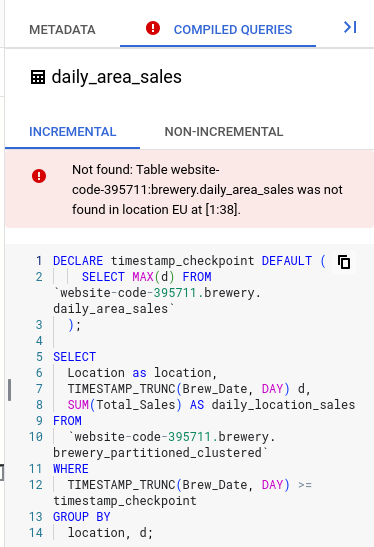
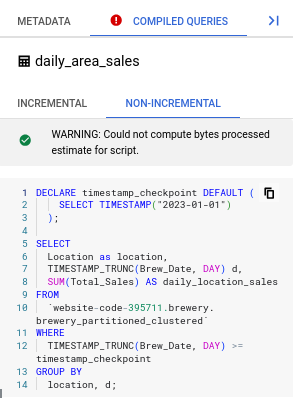
Don’t worry about it. We are creating an “incremental” table. Since we cannot increment something if it didn’t already exist, the error just highlights that. If you go to the non-incremental tab, it all looks good. After you execute this workflow for the first time, the error will disappear.
All that’s left to do is run this. We could do this by selecting the “Start Execution” button on top and following the UI:
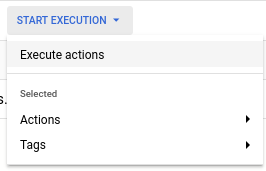
But let’s be a bit more formal and execute the code by creating release configurations and workflow configurations.
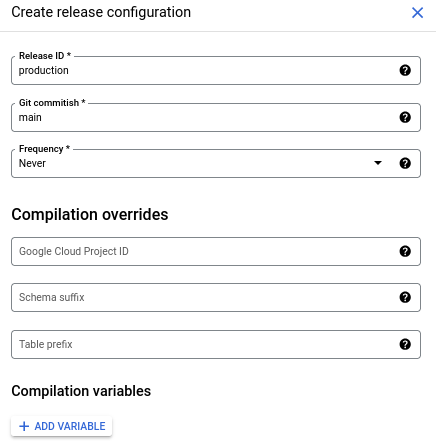
Create a release configuration
You can create a release configuration by the UI or through an API. The API is of course much more powerful and makes a great case for using it with CI/CD but we’ll reserve that later.
Release configuration is easily understood if you think of it like a function.
release_configuration = compile(code, config).
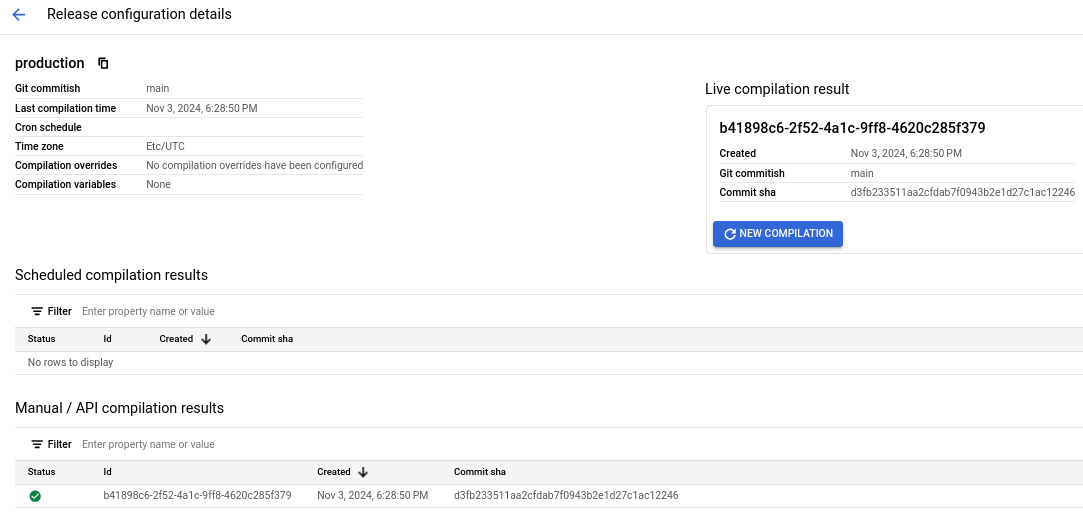
The “release” part of a release configuration is the “compilation result” of the code. Give it a name (release Id) and set the frequency at which these compilation results are to be generated. My settings are quite simple: “production” for the release id and “never” for the frequency.
Since a release configuration is the compiled result of SQLX, if you are using the release configuration as the source for pipeline executions (aka, workflow invocation in Dataform lingo), it means you must create a new compilation whenever a change happens. This is where the API comes in handy. Otherwise, you can just set a frequency and it gets compiled. For this example, since we chose “never”, the compilation result has to be created manually every time a change in the code needs to be reflected in the actual pipeline being executed.
The “configuration” part arises from that you can pass parameters to this compilation. This is where workflow_settings.yaml comes into play again.
We don’t need to override anything in this simple example, but let’s say we have a tablePrefix variable , we could use it store compilation results for staging and production for example. You can even pass custom variables using vars, for example, something like max_lookback. Taking the two together, we could say for staging environment, max_lookback is 1 month, and for production environment max_lookback is 1 year. And then, wrap this in the pre_operations block. Variables in workflow_settings.yaml are referenced using the dataform.projectConfig object. We’ll explore this in a future post.
Create a workflow configuration
Similar to the release configuration, it is easy to mentally map a workflow configuration to a function like so:
workflow_configuration = create_workflow(release_id, config)
The “workflow” part here is just the release configuration which has the compiled code.
The “configuration” part is how often you want to run this workflow (aka, “create the workflow invocation” in Dataform lingo) and which parts of the compiled code that needs to be executed.
The second part is more interesting. A Dataform “action” is the smallest executable unit in a workflow. In this example, the only Action we have is daily_area_sales . But we can have multiple actions in a single workflow. Actions can even depend on each other. An Action can be either selected directly in a workflow configuration or through tags (this is specified in the config block, refer to the SQLX file to see it).
Taken along with the ability to parameterize a release configuration, this becomes very powerful as you can specify, configure and execute pipelines in a very flexible way.
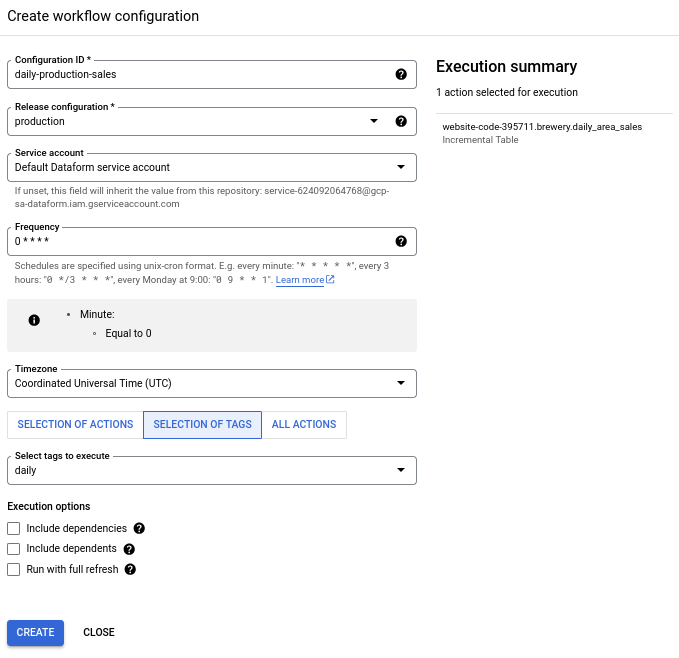
And that’s it! Dataform will schedule the execution of this pipeline nightly and you get daily aggregated sales data in the table.
Concluding remarks
And with that, a simple pipeline in Dataform is ready. There’s still a lot to talk about of course. In the upcoming posts, we’ll go a bit further in depth on things like variables, action dependencies, data quality tests, CI/CD and observability.