Parquet format - A deep dive : Part 1
Demystifying how Parquet works internally

Working mostly on Data Engineering, Machine Learning and Bayesian analytics.
The parquet file format is a well known data storage format that is famed for its "efficient storage" and "fast retrieval". I started this journey in an attempt to understand how spark and parquet work internally a bit better. It was a bit confusing for me to go over the material and the code, so I thought of writing down my thoughts in hopes it would be of help to myself and any others too.
To begin, there were few objectives that I wanted to meet:
What are the ideas / algorithms? that went into this data storage format?
How is data written / read?
Where is the codebase that puts it all together?
This series of articles is the output of the above questions. This article presents an overview and the following articles go deeper into it, I hope you'll find it of some utility.
Parquet overview
How is data stored?
Is parquet row-oriented or column oriented or hybird?
Broadly, there are three types of databases: Row-oriented, column-oriented and hybrid. There is good material on the web that explain them in greater detail, refer here[1] and here[2]. Though parquet is typically called as a columnar store, in my opinion, it is not strictly columnar. It follows a hybrid approach. The similarity comes from that both of these approaches do read data a column at a time, however traditional columnar stores tend to store each attribute or column as files independently of other columns. Parquet instead stores columns together as "row groups". A diagram can help in understanding the differences a bit better.
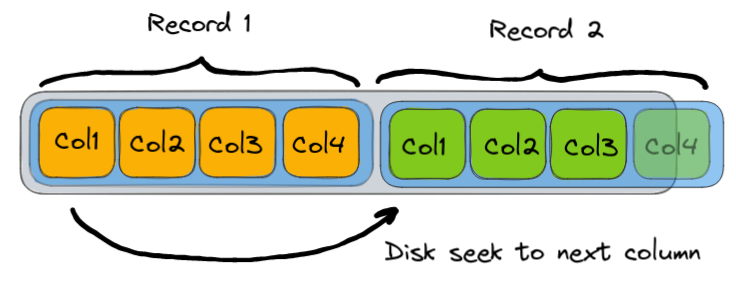
Row-oriented
Columns in a record are arranged one after another, this allows you to seek to a particular record quickly through index structures but if you want to retrieve lots of specific column data quickly as is common in analytical workloads, then we would have to seek to the next record, take that column values, move to the next one and so on.
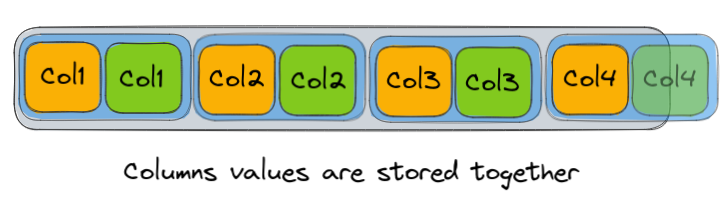
Column-oriented
The columns are stored together and typically stored independently of other column values. This allows for fast retrieval of vast amounts of data but tradeoffs advantages of row-oriented structures such as fast updates.
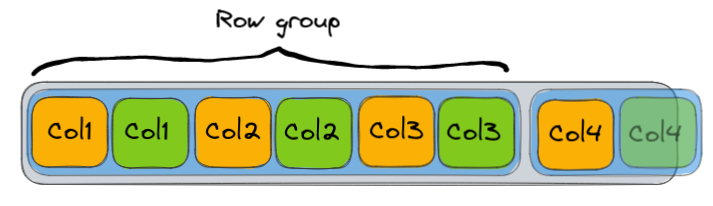
Hybrid
Hybrid does not have a strict definition as far as I can tell, it is implementation dependent. Parquet does it by grouping together column values like in the column oriented db, however they are not stored independently in files as it is traditionally done. Instead think of it as the columns of multiple records being packed together, so what we have is a group of records aka a "row group " with columns packed inside these row groups as chunks of data.
Physical layout and term definitions
The diagram for parquet's physical layout from https://parquet.apache.org/docs/file-format/.

Now for the terms used in describing parquet format. Most of the definitions listed here correspond to the image above and come from the parquet-format[3] library. There are a couple extra ones that come from code in parquet-hadoop module and parquet-column in parquet-mr[4] which I thought to add in as well.
Column chunk: A row is a bunch of columns with each column having a value. A column chunk is a chunk of values for that particular column.
Page / Data page: Column chunks are split into pages.
Row group: A group of column chunks.
Page header: Has metadata for this page. For example: number of values, repetition and definition levels which are used in the record shredding process, statistics such as min max which are useful in filtering, among others.
Footer: Contains metadata. Notably, file metadata and block metadata.
File metadata: Contains schema
Block metadata: Contains row count, list of column chunk metadata, path to this column, etc.
Encoding and compression schemes used
Parquet has a variety of encoding and compression schemes. Data is encoded using Run-Length encoding + bit packing hybrid. Another option that parquet can use for encoding is Delta encoding.
Parquet can store compressed data in its data pages. Snappy is the most popular compression scheme but parquet by default also supports gzip and zstd out of the box.
How is data written?
Record shredding
Sidebar: Whoever invented the term "record shredding" needs a raise, it sounds a lot cooler than record splitting.
We need a way to convert data stored as records into flat columnar data. And this data need not be flat, it can have structure. For example, if the data can be nested, can have array values, fields in records are optional and so on.
So how do we convert this into flat columnar data? This done using Dremel's record shredding algorithm[5]. The basic idea is that nested data is a tree of nodes at different levels, and what we do is associate each node with some metadata that lets us know if it is repeated, if the path to the node has NULL values and so on so that we do not lose the record structure information.
Writing data into parquet is documented in part 2 of this series.
How is data read?
Record assembly
Reading the data from parquet back into records requires a reconstruction of the original record structure. This is a little bit more complex than the record splitting process but at a high level it uses the metadata from before that we use to encode the record structure during the record shredding process. What we need is a way to arrange the nodes in relation to each other so that the original record can be reconstructed.
This process is documented in part 3 of this series.
Reading parquet data in spark vs. parquet-mr
When it comes to implementation of reading parquet data, there are two libraries: the spark way and the parquet-mr way.
Parquet-mr itself has two APIs, an older api that used to read all the data, and filter records during assembly and a newer API that skips over pages by looking at the metadata in each block which is much faster. Spark uses a vectorized approach to read data, which means it reads columnar data in parquet files in batches for each column. It is based off parquet-mr's implementation to some extent. Spark has a fallback mechanism to parquet-mr's code which can be set in the spark configuration. There are other tricks which are used to improve reading speed: Projection pushdown, predicate pushdown, bloom filters among others.
Grokking the source code
In part 4, we will look at some of the key classes, methods used in spark and parquet-mr along with the code flow. This is useful when you want to navigate the code base.
References
[2] https://www.youtube.com/watch?v=Vw1fCeD06YI
[3] https://github.com/apache/parquet-format
[4] https://github.com/apache/parquet-mr
[5] https://storage.googleapis.com/pub-tools-public-publication-data/pdf/36632.pdf